Disclaimer: LLM Agents wrote the code and the bugs. The ideas and most of the wording in this blog series are mine, but edited by LLMs because I am an engineer, not a copywriter. I’ve reviewed it to ensure it sounds like me, but if you spot weird phrasing, blame the robot.
Prefer the short version? Start here: I Built a Family Planner We Actually Use (and It Costs £0/month)
Family data falls into two categories.
- Internal: “Dinner at Grandma’s”. We control this.
- External: “Inset Day” or “Recycling Collection”. We do not control this, it changes without warning, and forgetting it causes chaos.
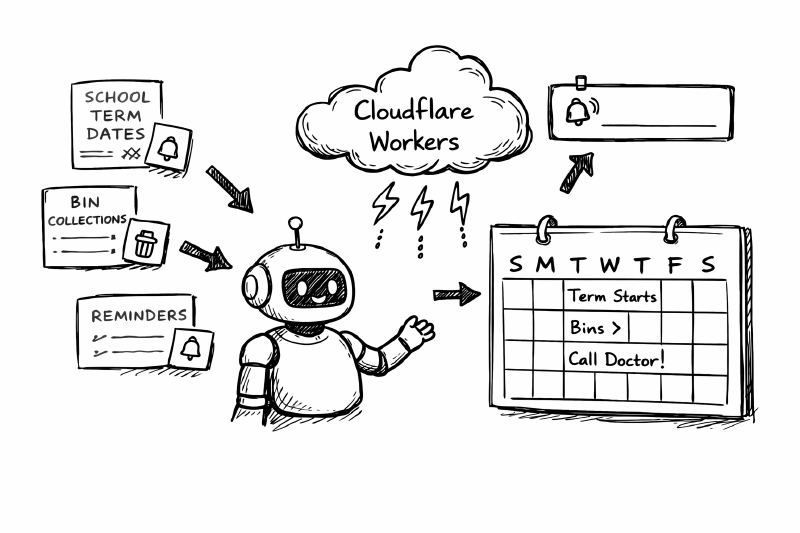
I wanted the planner to handle the second kind. This meant writing integrations.
In a professional context I’d look for an enterprise API with an SLA. In the context of my local council and school I’m looking at messy HTML and obscure JSON endpoints.
This is how I used Cloudflare Workers to ingest annoying schedules without polluting my clean database.
The “Overlay” Strategy
I stood firm on my data rule: External data never touches the WeekDoc.
If I merged school dates into our primary weekly JSON, a scraper bug could corrupt our personal schedule. Instead, Term Dates and Bin Collections are stored as separate KV documents. The UI renders them as visual overlays.
If the school website changes its layout and my scraper fails, the overlay disappears, but our family calendar remains intact. This is standard defensive coding.
Scraping School Dates
Schools generally provide PDF links or HTML tables rather than APIs.
I wrote a refresher script (src/shared/schoolDatesRefresh.ts) that uses HTMLRewriter to scrape the term dates. This code is brittle and boring to write.
I let the Agent write it. I gave it the HTML structure and instructed it to extract the dates, normalize them to ISO strings, and hash the result.

Term dates as data, not a link you have to remember.
If the hash hasn’t changed we don’t write to KV. This keeps the “Last Updated” timestamp meaningful. We assume the scrape is hostile; if the data doesn’t validate strictly, we discard it.
Bin Collections
I prepared to scrape the council website but found a hidden backend API. It requires a UPRN (property identifier) which I injected via environment variables.
This runs on a scheduled Worker. It fetches the data, normalizes it, and stores it in its own KV key. The UI checks for a bin overlay for the current week and renders it.
Push Notifications
I originally avoided Push because it feels intrusive. After missing an event because I didn’t look at the phone, I changed my mind.
The architecture is simple. A Service Worker handles the incoming push. A Dispatcher Worker runs on a cron trigger every minute. We track sent message IDs in KV to ensure we don’t spam the family if the worker retries.

Enable/disable/test push per device. No hidden magic.
This is the only part of the app that feels like traditional infrastructure.
This is unglamorous plumbing, but it is necessary. It is also where LLM Agents excel. I can paste a curled HTML response into the chat and ask for a robust parser using Zod. The Agent handles the regex, and I handle the architecture that ensures a bad regex doesn’t bring down the app.
Next: Part 4: Fast Capture: Universal Add and the “Trust Layer”